Systematic opportunity discovery starts with better research. We've built an AI research platform at Stackpoint that automates how we uncover high-impact opportunities in legacy industries, like real estate, finance, and insurance.
This system doesn't just help us research faster, it helps us research better. It’s designed to supplement and supercharge our team's critical thinking, not replace it.
When we're evaluating a new venture opportunity, we can instantly access synthesized insights from relevant industry developments over the past years. When we're advising portfolio companies, we can quickly identify which trends are worth paying attention to, and which are just noise. It also helps us identify potential founders and validate market timing.
The result is what we call "proprietary research" - insights that aren't available to anyone else because they come from our unique combination of curated sources, specialized processing, and institutional memory.
How We Improved Traditional Research Methods With AI
Before Gen AI, we used to spend hours manually reading reports, browsing websites, and listening to podcasts to stay current with industry developments. But even the most dedicated researchers could process only a fraction of the relevant information produced daily.
There was also the issue of cognitive bias. Researchers naturally gravitate toward familiar sources, prioritize what confirms their existing views, and miss out on emerging trends that don’t yet fit known patterns. Even with the best intentions, these blind spots can narrow thinking and lead teams to chase what’s familiar, not what’s valuable.
Additionally, context sharing was also difficult. Information was usually locked in slide decks, docs, or individual brains. This made it harder for teams to collaborate effectively or bounce ideas off each other. Instead of building on shared understanding, they often worked in silos.
This led to missed opportunities, delayed insights, and research that's always playing catch-up rather than staying ahead of trends.
We all know Gen AI can improve the above process, but going beyond the obvious AI use cases, we built a system that creates focused, industry-specific knowledge bases. Think of it as having a research team that never sleeps, never misses a relevant development, and can instantly connect patterns across thousands of documents.
The system works in three layers:
Content ingestion: We automatically ingest and process content from carefully selected industry sources; newsletters, reports, podcasts, industry publications, etc. We curate them from the sources we trust most in legacy industries.
Intelligent processing: We don't just have one, but multiple agents to process and analyze the content in different ways with human oversight. They extract key themes, identify emerging trends, and create searchable summaries. When a two-hour industry podcast gets published, our system processes the entire transcript, indexes the key insights, and makes them searchable within minutes.
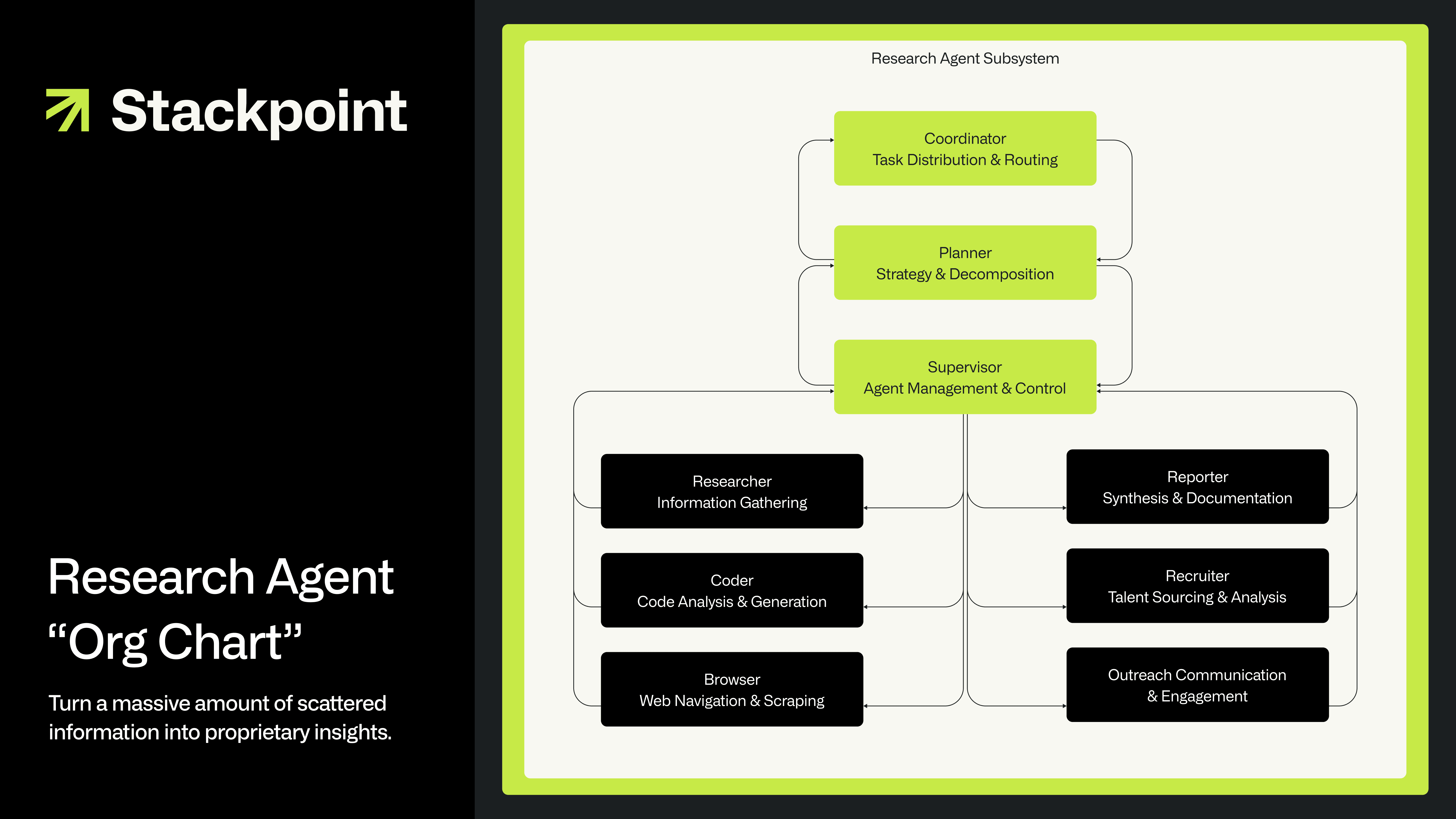
Enhanced research: The most powerful part is our research agent subsystem. It goes beyond surface-level answers by breaking down high-level questions like “What emerging trends do you see in PropTech?” into focused research tasks. Multiple AI agents investigate from different angles, then synthesize the findings to reveal patterns and insights that would otherwise be easy to miss. It’s designed to help our team connect the dots, not just collect data.
The AI Agents Fueling Our Research System
Our research system delivers faster, high-quality insights at scale (without bias or fatigue) and builds on past knowledge to connect the dots over time.
We achieve this sort of long term memory by storing diverse content across a series of collections in a vector database. Alongside this, we’ve built a platform that supports the development of various features. The high-level diagram below shows how it all works:
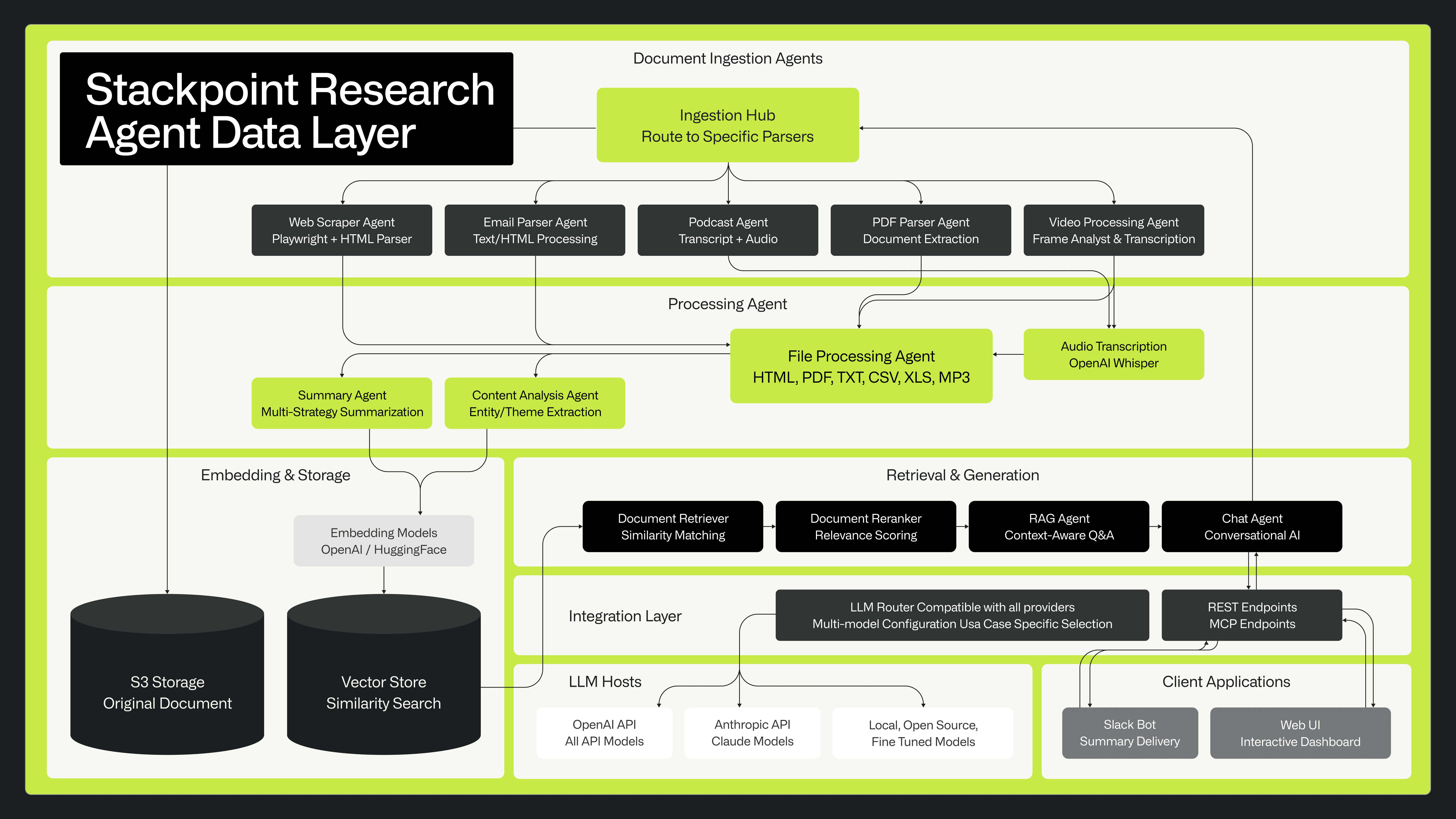
One system we have built within our application platform is a research agent coordination system that is able to generate insights from a combination of open web search - similar to Deep Research flows on ChatGPT.
What makes our system unique is that it enriches each query during the research process with curated context pulled from our internal knowledge base of previously gathered insights.
When we trigger a top level query against our research system, the below specialized AI agents work behind the scenes:
The Researcher handles document retrieval and analysis. It doesn't just find relevant documents, but also uses advanced ranking models to ensure the most relevant information surfaces first. This solves a common problem with AI research: getting buried in irrelevant results.
The Coder performs quantitative analysis that goes beyond what language models can do alone. When we need statistical analysis or data processing, this agent writes and executes Python code to crunch the numbers properly.
The Browser expands our research beyond our curated knowledge base when needed. It can investigate specific companies, validate claims, or gather additional context from the web, but only when our internal knowledge base doesn't have the answers.
The Coordinator ties everything together. It takes complex research questions, breaks them into manageable tasks, and orchestrates the other agents to execute a comprehensive research plan.
We built a custom chat interface that lets our team interact with and manage agents, as well as ask complex questions directly. Alongside this, we provide access to external tools like ChatGPT and Claude through an MCP, so there’s no need to switch between apps.
How We Built Our AI Research System
Our engineers built custom data pipelines, implemented advanced document processing, and created sophisticated retrieval systems that understand context and relevance. The technical depth gives us capabilities that generic AI tools can't provide.
Overall, the goal of our data processing pipelines in terms of implementation was to ensure that they are stable and accessible for everyone throughout Stackpoint. As a result, we had to be mindful of a couple of critical concerns:
1. What is most convenient for Stackpoint users?
We decided to make the client layer as simple as possible. For data ingestion, team members can interact with the application either through an API or a Slack bot.
Beyond human triggered interfaces, many data ingestion flows, such as emails and podcasts, can be fully automated so no human engagement is required to take in data as it becomes available.
2. What will require minimal long-term maintenance?
We have carefully selected where to write custom business logic for document processing, and when to offload document processing to high quality vendors, such as LlamaCloud. These tools handle complex document ingestion and vector indexing effectively, allowing us to offload standard flows.
This allows us to focus on more specialized cases, such as podcast and video ingestion, with our custom logic in order to create a consistent experience with minimal maintenance overhead for our engineers.
This is the kind of infrastructure advantage and technical decision making that compounds over time without accumulating tech debt.
Where We’re Headed and What That Means for You
The goal isn't to replace human judgment, it's to give our team advanced research capabilities, so we continue to be the best venture studio dedicated to building and investing in vertical AI companies in legacy industries. Our competitive advantage lies in decades of company-building experience and a full-stack team with deep AI capabilities.
For founders, this means access to advanced research infrastructure, data-backed decisions, and a partner whom you can trust. If you're a repeat founder eager to build, whether you have a fully formed idea or are still exploring, let’s talk.


